


Posts in category Life in Delft
Homomorphic Encryption
Today, a lot of data is stored in the cloud. But what is a cloud? It is basically someone else’s computer with lot more storage space than regular laptops and desktop computers. Knowing this, some people encrypt the data before sending it to the cloud so that neither the owner of the cloud or a hacker who obtains access to the cloud can read the data. But what if the data that is encrypted is a file which you want to modify after uploading to the cloud?
One way would be to download the file from the cloud, decrypt it, modify it and then upload the modified file back to the cloud. Another way would be to decrypt the file online and modify it. But this would leave the file vulnerable. Thus this method can be ruled out. The first method is viable if the file is of the size that your computer can handle. What if you want to search for a keyword in a large number of files that you have encrypted and stored in the cloud? Assuming that these files are confidential, the only reason you are storing them in the cloud is due to lack of space on your computer, it is not viable to download the entire database and find the files with the keyword. So what will you do?
You can use homomorphic encryption. Homomorphic encryption is a form of encryption which allows processing of encrypted data and generate an encrypted result which, when decrypted, matches the result of operations performed on the plaintexts. It was first mentioned in 1978 by Rivest, Adleman and Dertouzo in their paper “On data banks and privacy homomorphisms”, but it took three decades for the first fully homomorphic encryption scheme to be proposed. In those thirty years, partially homomorphic schemes were proposed. RSA cryptosystem, that is widely used today, in its unpadded form is multiplicatively homomorphic, wherein the multiplication of two ciphertexts on decryption gives the product of plaintexts. ElGamal cryptosystem is another multiplicatively homomorphic scheme while Paillier cryptosystem is one of the additively homomorphic cryptosystems.
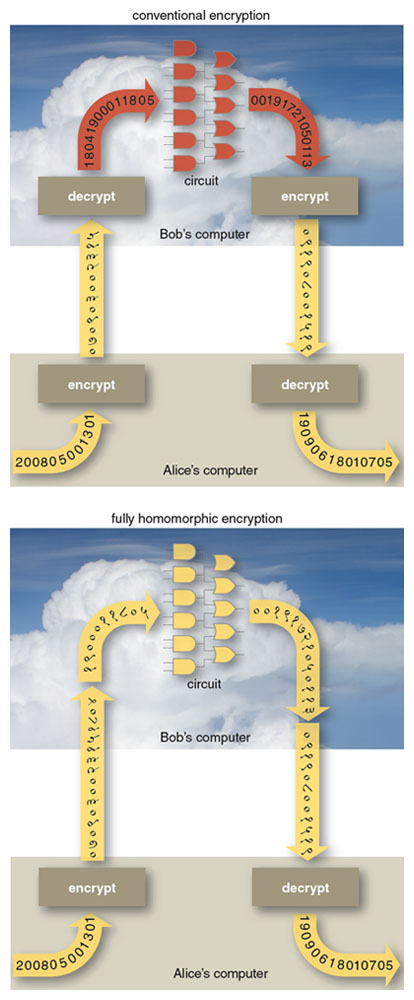
Image Source: http://www.americanscientist.org/issues/pub/2012/5/alice-and-bob-in-cipherspace/1
Needle in the haystack?
At the end of January, USENIX Enigma Conference was held in San Francisco. The program consisted of talks from the security community, both academic and industry. One of the talks that caught my attention is the talk by Nicholas Weaver titled The Golden Age of Surveillance, which focuses on the concepts behind bulk surveillance and its success.
In the talk Nicholas cleared two misconceptions about bulk surveillance. First, surveillance is not like needle in the haystack. Instead it is about the numerous needles and recognizing the one which is of interest. Second, it is not about connecting the dots. Collecting multitude of data gives so many dots that any constellation could be drawn.
Instead surveillance can be looked at as a two-step process. First to cast an internet-wide net, “drift nets”, and extract content derived metadata. One of the applications he mentions is PGP or Pretty Good Privacy. PGP which is used to send encrypted emails provides sufficient metadata though the data itself is hidden. Another example is .doc files which contain the author name. The author name can be matched to other documents that were captured in the net to derive more information.
The second step involves “pulling threads to get results”. For this he gives an example of how an anonymous user in an Internet Relay Chat (IRC) can be identified using Signal Intelligence and Computer Network Exploitation. Using internet wiretapping, the traffic is filtered and certain types of data such as videos is ignored. Then the source and destination IP address of the packets sent over the network is hashed in the load balancer and in the processing nodes, the packets are reassembled and the headers are parsed to derive the metadata. Finally he mentions how the information obtained through wiretapping can be used to inject packets (Quantum Insert) and take over the, once anonymous, user’s computer.
Articles on Quantum Insert can be found here and here. The talk by Nicholas can be viewed here.
Proof-Of-Work
The blocks in the block chain are created by nodes in the network, which called miners. A miner receives transactions from other nodes in the Bitcoin network. Every transaction is verified on arrival so that an attacker cannot maliciously transmit transactions to double spend a bitcoin. But the transactions are received in a non-deterministically which causes blocks to differ from miner to miner. Thus there needs to be a method to obtain consensus on the order of transactions among the nodes. Bitcoin uses a Proof-Of-Work (POW) system based on Hashcash.
As part of the POW system, a nonce is added to every block. The nonce is just a number but it is only accepted if the hash of the whole block begins with a certain number of zeros. Miners have to find the correct nonce for their block. The miner who finds the block receives a transaction fee as incentive to expend CPU time and electricity. It is possible that multiple miners find a valid nonce at approximately the same time and notify parts of the network of their newly found block. To solve this inconsistency, Bitcoin nodes save both branches and continue using the longest branch. At some point one branch will become predominant in the network as more nodes will dedicate computing power to extend this branch and the smaller branch is then abandoned.
The average time taken to find a block in a bitcoin network should be 10 minutes. Every two weeks, the number of zeros needed in the beginning of the hash of the transaction is adjusted to compensate for the fluctuating speed of the network to find a block. The difficulty of finding a block is directly proportional to the number of zeros.
One of the alternatives to POW is Proof-of-Stake. The video below explains it in comparison to POW.
Block chain
Block chain is the main technological innovation of Bitcoin. It was introduced by Satoshi Nakamoto as a timestamp server as part of the Bitcoin protocol. A block chain is a public ledger shared by all nodes participating in a system based on the Bitcoin protocol, that is, all nodes in the network have a copy of the entire block chain. A full copy of a block chain contains every transaction ever executed. Thus it is a proof of all the transactions on the network. But what is a transaction? A transaction is a transfer of Bitcoin value which is broadcast to the network and collected into blocks. A transaction typically references previous transaction by concatenating it with the public key of the new owner and hashing it. The current owner digitally signs this hash and sends it along with the public key of the new owner. A payee can verify the signatures to verify the chain of ownership.
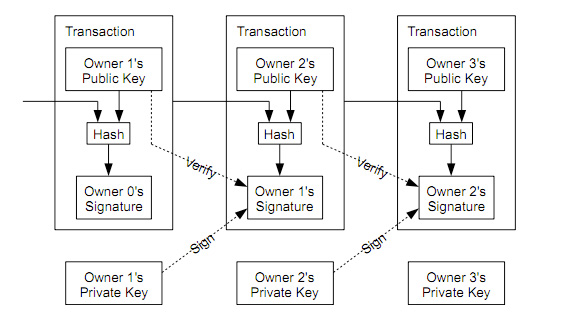
Every block in the block chain contains a hash of the previous block such that a chain of blocks is created from the first block of the chain, also known as genesis block, to the current block. This way the blocks are arranged in chronological order. Due to the Proof-Of-Work, it is also computationally infeasible to modify a block as every block that follows must also be regenerated. These properties prevent double-spending in bitcoins. Double spending had been a threat to digital currencies before bitcoin. This is because unlike physical money, digital currency can be easily duplicated.
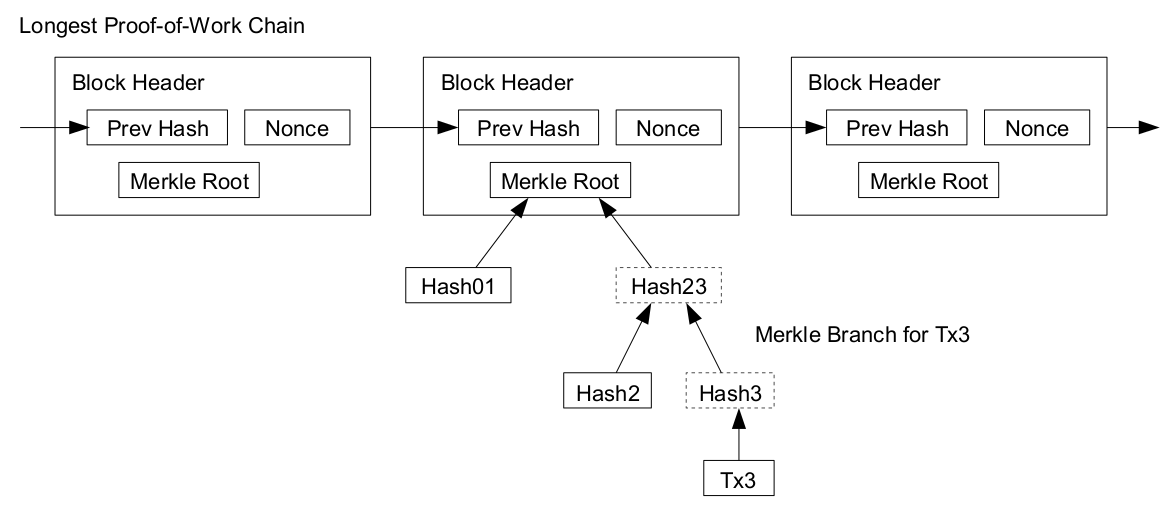
Considering all nodes in the network have a copy of the block chain, if every transaction is added to the block chain, then the size of the block chain will will sooner or later become to large. Instead just the merkle root of the merkle tree formed by the transactions to find a block can be used. To compute the merkle root, copies of each transaction is hashed, and the hashes are then paired and hashed, paired again and hashed again until a single hash remains, the merkle root of a merkle tree. The merkle root is stored in the block header. Transaction verification can be performed using Merkle Hash trees without checking the transaction itself.
The technology used when you borrow books from the library
In my last blog post I briefly described RFID technology. In this blog post I will give one implementation example as seen in the TU Delft library.
The books in the library have a paper thin passive RFID tag attached to the backcover. This tag contains information related to the book, mostly in the form of a unique identification number. When you want to borrow a book, you can use one of the self checkin/checkout stations. You need to place the campus card (if student or employee of TU Delft) or library membership card on the card reader to identify yourself. On placing one or several books on the self checkin station, the RFID tag is read by the reader. Placing multiple books on top of each other should be avoided as the reader may not be able to identify individual books due to tag collision. The reader communicates with a server to inform that one or several books have been checked-in by the identified visitor and this information is stored in the database. When you return (checkout) the books to the library, a similar sequence of events take place. If you require assistance, the librarian at the service desk can help you by using the checkin/checkout station available at the service desk. While leaving the library, you pass through exit sensors (another reader with a longer detection range than checkin/checkout stations) which verifies if the book has been checked-in. If the book has not been checked-in, an alarm is triggered.

Normally you will be exposed to RFID technology in the above mentioned form. Sometimes, the RFID tag attached to the book may not have the right information or a new book may have arrived. In such a scenario a conversion station behind the service desk is used by the librarian to write the required information on a new tag and attach it to the book. RFID technology also makes it easier for the librarians to search for individual books requested from the depot and for inventory checks.
RFID
At the TU Delft, one can observe the widespread usage of Radio Frequency Identification (RFID) technology. The campus cards have a RFID tag in them, the doors of the rooms in the university have a RFID reader which is used for access control, while in the library RFID systems are used in multiple ways such as self-checkin and checkout stations, exit sensors, etc. Traveling by public transport in the Netherlands requires OV-Chipkaart which has a RFID tag.
The basic elements of RFID have been known since the Second World War. Airplanes had an identification signal which enabled the ground stations to distinguish their own aircrafts to those sent by the enemy. RFID technology works on the principle of radio frequency transmission-reception. Most RFID systems use the unlicensed spectrum. Low Frequency (125-134.2 KHz) and High Frequency (13.56MHz) bands are used in cheaper systems and these are used for example in animal tagging. Ultra High Frequency bands and ISM bands are used in smart cards and item management (as in the library).

An RFID system is made up of two components – a tag (or transponder) and a reader. A tag, which represents the actual data carrying device of an RFID system, normally consists of a an antenna and an electronic microchip that contains a radio receiver, a radio modulator for sending response back to the reader, control logic, some amount of memory and a power system. There are two types of tags – passive and active. An active transponder possesses its own voltage supply (or battery) while a passive transponder does not. An active tag has a larger reading range and is less commonly used due to its costs and shorter shelf life. A passive tag is only activated when it is within the response range of a reader. The power required to activate the tag is supplied through the contactless coupling unit as is the timing pulse and data. There are also semi-passive tags which have a battery but use the reader’s power to transmit a message back. It must be noted that some tags are programmed by the manufacturer and are ‘read-only’ while others are reprogrammable.
A reader are continually on and typically send a radio signal and listen for a tag’s response. Depending on the RFID system, the reader communicates by Amplitude modulation (AM), Phase modulation (PM) or Frequency modulation (FM). The tag detects the energy and communicated with the reader by varying how much it loads its antenna. By switching the load rapidly, the tag establishes its own carrier frequency and sends back the tag’s serial number and some other information as well. Most tags transmit only a number which the reader sends to a computer. If the tag is used for access control, then the computer will check if the number is in the list of numbers that is allowed access. If it is present, then the computer might energize the solenoid to unlock the door.
References:
1. Lahiri, S. ( 2006). RFID Source Book. IBM Press.
2. https://www.rfidjournal.com/
Post-Quantum public key cryptosystems
Public-key cryptosystems, such as RSA, Diffie-Hellman and Elliptic Curves, which are in use today are based on Integer Factorization Problem (IFP) or Discrete Log problem (DLP). Their strength lies in the difficulty of determining the private key when the public key is known. These algorithms are part of internet standards, for example TLS and GPG, and are used for key exchange. But these algorithms can potentially be broken in polynomial time by Shor’s algorithm if quantum computers become operational. This means we need to look for cryptosystems which will not be susceptible when attacked using quantum computers.
In 1978, two years after the publication of the seminal paper by Diffie and Hellman on the use of private and public keys for cryptography, McEliece proposed a public key cryptosystem based on algebraic coding theory. In this system, a generator matrix is used as the private key and a transformed version of it as the public key. The security of the system lies in the hardness of decoding a large linear code with no visible structure. An attacker would is forced to use syndrome decoding while the person in possession of the private key could use fast decoding algorithms. The original McEliece cryptosystem, based on binary Goppa codes, has not yet been broken in polynomial time. The main advantage of this system is the fast encryption and decryption mechanism, which is two or three magnitude faster than RSA. One might wonder why this algorithm has not found widespread implementation yet. There are two disadvantages which are the main reasons for the lack of popularity of this system. First, the key size is very large and second, information rate is very low (k/n = 0.5, which means there are as many redundancy bits as information bits). This increases the bandwidth required which makes the system prone to transmission errors. The original system required public keys of size in the order of hundreds of kilobits while RSA uses a key size of 1024, 2048 and 4096 bits.
Researchers have been working to reduce the key size of the McEliece cryptosystem so that it can be used in practical applications. To reduce the key size many alternatives to Goppa codes have been proposed. One such alternative is based on Low Density Parity Check (LDPC) codes. Though it seemed to be an attractive alternative, it was possible to search for low weight codewords in the dual of the public key. In order to counter this weakness the use of Quasi-Cyclic LDPC codes has been proposed. QC-LDPC is an effective alternative to reduce the size of public keys of McEliece cryptosystem. This system requires a public key of size about 50 kilobits to achieve a security equivalent of 2048 bit RSA. This is a reduction of key size by a magnitude of ten from the original McEliece cryptosystem while maintaining the advantage of fast encoding and decoding.
Extended Mind
One of the most popular dualism is the substance dualism introduced by Rene Descartes. Descartes distinguished the mind from matter and claimed that they are fundamentally different. He describes the mind as a thinking substance and matter as an extended substance. If matter and mind are different substances, is there a boundary for the mind? It is a common notion that the mind is nothing more than the working of the brain which resides in the skull. Hence the mind is in the skull.
Andy Clark and David Chalmers, in their seminal work ‘Extended Mind’ in 1998, claim that cognition is not restricted to the head but can be extended using different artifacts. This challenges the view that the mind is a little black box in the head. The basic idea of ‘Extended Mind’ is that the mind is not constituted just by the brain but also by electronic devices, papers and other items which are outside the head. The location of the mind is irrelevant. It is the functionality that is considered here. It doesn’t matter if the calculation is performed in the head or using a calculator.
Technology has become an integral part of who human beings are. Technology doesn’t just play a passive role but instead influences decisions. There is certain sense of dependency on books, computers and calendars. If a person spends a large part of the day with their mobile phone, to make calls, find routes to new places, read news articles, etc. is the mobile phone part of the person’s mind or is it still just an external device? Would the mental state of the person change is the mobile phone is broken or switched off?
Even if all the electronic devices and papers are wiped out of the surface of the earth, aren’t humans influenced by their fellow beings and dependent on them? Clark and Chalmers question, “And what about socially-extended cognition? Could my mental states be partly constituted by the states of other thinkers? We see no reason why not, in principle.” Conversations often involve ‘Remind me to send X to Y’. How different is this from setting reminders on the mobile phone? How different is it to remembering in the head? Aren’t these complimentary?
Image Source: https://xkcd.com/903/
Data about data
“Metadata absolutely tells you everything about somebody’s life. If you have enough metadata you don’t really need content.”
-Stewart Baker
Many people do not feel safe when they know that another entity is collecting information about them. If an individual collects information about you and uses this data to follow you, then it is called stalking. But if an organization wants to collect information about you and millions of others, often it is tagged as security measure. Organizations require a lot of storage space to store data. Earlier the storage space used to be in the form of large rooms filled with papers, now it is in the form of hard drives. With increasing amount of data about each person, organizations which want to store data realized that they will run out of space or will need to spend more to add space. They had to come up with a way to store information in limited space.
Individuals who care for their privacy might be relieved that organizations may after all not collect data about them. But this is where metadata enters the picture. Metadata is data about data. For example, data would be the recording of a phone call Bob made to Alice while the metadata would include the time of call, duration of call, location of your phone, location of your friends phone and of course both your phone numbers and name. Storing a phone call would require many megabytes of space while the metadata requires only few kilobytes of space. Many might question, what organizations can do with phone metadata without knowing the contents of the call.
Phone metadata provides organizations with enough information to map the life of people. Your location is recorded in order to provide continuous connectivity. The user does not need to make calls in order to give away their location. Now assume the organization only collects the location metadata of hundreds of users, it can trace the movement of people and basically draw a map. Looking at the overlapping location of multiple users at a particular time, it can be known with high probability that this group of users are associated with each other. If the location happens to be a football stadium owned by the local club, and the same group of users’ meet at the place every time there is a game being played, it can be known that they are followers of this particular club. Note that the users did not voluntarily mention about their favourite football club. But it was known just by tracking their location. This is a trivial example with only one kind of metadata. So much more can be known if other types of metadata such as online search terms are also known by the organization.
A lot of people would not mind letting others know of their favourite football club. But let us say that two people are in an intimate relationship and want to keep it a secret. They call each other often late in the night. The call duration is often more than an hour long. But after few months, the duration of calls reduces and after few more months the frequency of calls also becomes irregular. Using this kind of metadata, it can be assumed that there was a relationship between these two people which has ended. When there is metadata, who needs data?
Education
“Education is the ability to listen to almost anything without losing your temper or your self-confidence.”
-Robert Frost
During one of the discussions I had during high school, I was asked if the knowledge gained through books and what we study in order to obtain a degree are what I would call education? As a sixteen year old who had not thought enough about education, but rather been ‘part of a system’, I was convinced that my answer was NO.
Over the past few years my belief in my answer that day has only grown stronger. I still may not be able to define what education is and I am not sure if I want to either. But it is certainly more than just obtaining multiple degrees. This does not mean that I disregard University education. University education has its own value in the current system and certainly provides a good foundation for people to fall back on. But I think education is less about teaching and more about learning and living. Learning from different sources about different things and entities, incorporating them, forming perspectives, acknowledging that others can have different opinions and have the ability to discuss peacefully and finally be willing to change if need be. It is not about knowing everything but about having a sense of curiosity. In short education is to live and let live.
I think, the TU being a technical university, has made an effort to allow students to look beyond the realms of their university degree. Studium Generale is one such organization in the University which provides opportunity for students. In the form of VOX and SG Academy, students have the opportunity to think and share their opinions without having the necessity to be right or correct and also listen to other’s perspective and have a fruitful discussion.
There are so many simple things that we overlook in our daily lives. These are often questions that are discussed in SG Academy. One such question is What is the relationship between math and reality? Mathematics plays an important role in our lives and yet it is considered that a common man has no knowledge of a major chunk of theoretical Mathematics. But why does mathematics play a vital role in our lives even though we are so often ignorant of the principles involved in our daily activities? Do we need to know it all? Is it any different from so many languages which have symbols that have a specific meaning?
https://www.youtube.com/watch?v=AJgkaU08VvY