


Posted in 2016
Homomorphic Encryption
Today, a lot of data is stored in the cloud. But what is a cloud? It is basically someone else’s computer with lot more storage space than regular laptops and desktop computers. Knowing this, some people encrypt the data before sending it to the cloud so that neither the owner of the cloud or a hacker who obtains access to the cloud can read the data. But what if the data that is encrypted is a file which you want to modify after uploading to the cloud?
One way would be to download the file from the cloud, decrypt it, modify it and then upload the modified file back to the cloud. Another way would be to decrypt the file online and modify it. But this would leave the file vulnerable. Thus this method can be ruled out. The first method is viable if the file is of the size that your computer can handle. What if you want to search for a keyword in a large number of files that you have encrypted and stored in the cloud? Assuming that these files are confidential, the only reason you are storing them in the cloud is due to lack of space on your computer, it is not viable to download the entire database and find the files with the keyword. So what will you do?
You can use homomorphic encryption. Homomorphic encryption is a form of encryption which allows processing of encrypted data and generate an encrypted result which, when decrypted, matches the result of operations performed on the plaintexts. It was first mentioned in 1978 by Rivest, Adleman and Dertouzo in their paper “On data banks and privacy homomorphisms”, but it took three decades for the first fully homomorphic encryption scheme to be proposed. In those thirty years, partially homomorphic schemes were proposed. RSA cryptosystem, that is widely used today, in its unpadded form is multiplicatively homomorphic, wherein the multiplication of two ciphertexts on decryption gives the product of plaintexts. ElGamal cryptosystem is another multiplicatively homomorphic scheme while Paillier cryptosystem is one of the additively homomorphic cryptosystems.
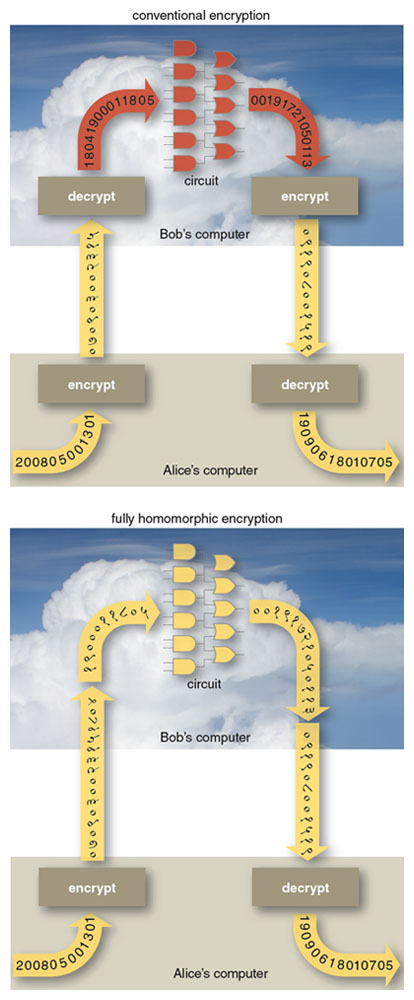
Image Source: http://www.americanscientist.org/issues/pub/2012/5/alice-and-bob-in-cipherspace/1
Needle in the haystack?
At the end of January, USENIX Enigma Conference was held in San Francisco. The program consisted of talks from the security community, both academic and industry. One of the talks that caught my attention is the talk by Nicholas Weaver titled The Golden Age of Surveillance, which focuses on the concepts behind bulk surveillance and its success.
In the talk Nicholas cleared two misconceptions about bulk surveillance. First, surveillance is not like needle in the haystack. Instead it is about the numerous needles and recognizing the one which is of interest. Second, it is not about connecting the dots. Collecting multitude of data gives so many dots that any constellation could be drawn.
Instead surveillance can be looked at as a two-step process. First to cast an internet-wide net, “drift nets”, and extract content derived metadata. One of the applications he mentions is PGP or Pretty Good Privacy. PGP which is used to send encrypted emails provides sufficient metadata though the data itself is hidden. Another example is .doc files which contain the author name. The author name can be matched to other documents that were captured in the net to derive more information.
The second step involves “pulling threads to get results”. For this he gives an example of how an anonymous user in an Internet Relay Chat (IRC) can be identified using Signal Intelligence and Computer Network Exploitation. Using internet wiretapping, the traffic is filtered and certain types of data such as videos is ignored. Then the source and destination IP address of the packets sent over the network is hashed in the load balancer and in the processing nodes, the packets are reassembled and the headers are parsed to derive the metadata. Finally he mentions how the information obtained through wiretapping can be used to inject packets (Quantum Insert) and take over the, once anonymous, user’s computer.
Articles on Quantum Insert can be found here and here. The talk by Nicholas can be viewed here.
Bitcoin and scalability
For the past few months, questions about the scalability of Bitcoin has been increasing and the developer community has attempted to come up with a solution. But the Bitcoin community is divided over the solutions and as mentioned here, it seems like an election where things are getting heated. As Bitcoin is based on consensus, a change cannot be made if a consensus is not reached.
Currently Bitcoin handles about 7 transactions per second while it has been claimed that the number is lower. Compare this to the 4000 transactions/second that VISA can handle, we see the gap in scalability. In order to scale Bitcoin, increasing the maximum block size (which is currently 1MB) is a necessity. More complex solutions, such as Segregated Witness proposed by Pieter Wuille at Scaling Bitcoin Conference in Hong Kong last December has found support in the community. Segregated Witness removes the signature from the transaction and stores it in a separate data structure, thus reducing the size of the transaction.
Gavin Anderson describes in his blog,
For example, the simplest possible one-input, one-output segregated witness transaction would be about 90 bytes of transaction data plus 80 or so bytes of signature– only those 90 bytes need to squeeze into the one megabyte block, instead of 170 bytes. More complicated multi-signature transactions save even more.
But why is Bitcoin scalability important? The Bitcoin network is congested and small increase in traffic leads to “dramatic changes in network conditions”. Transactions take minutes and sometimes hours to be executed. How many users find it acceptable to wait that long for their transactions to be executed?